
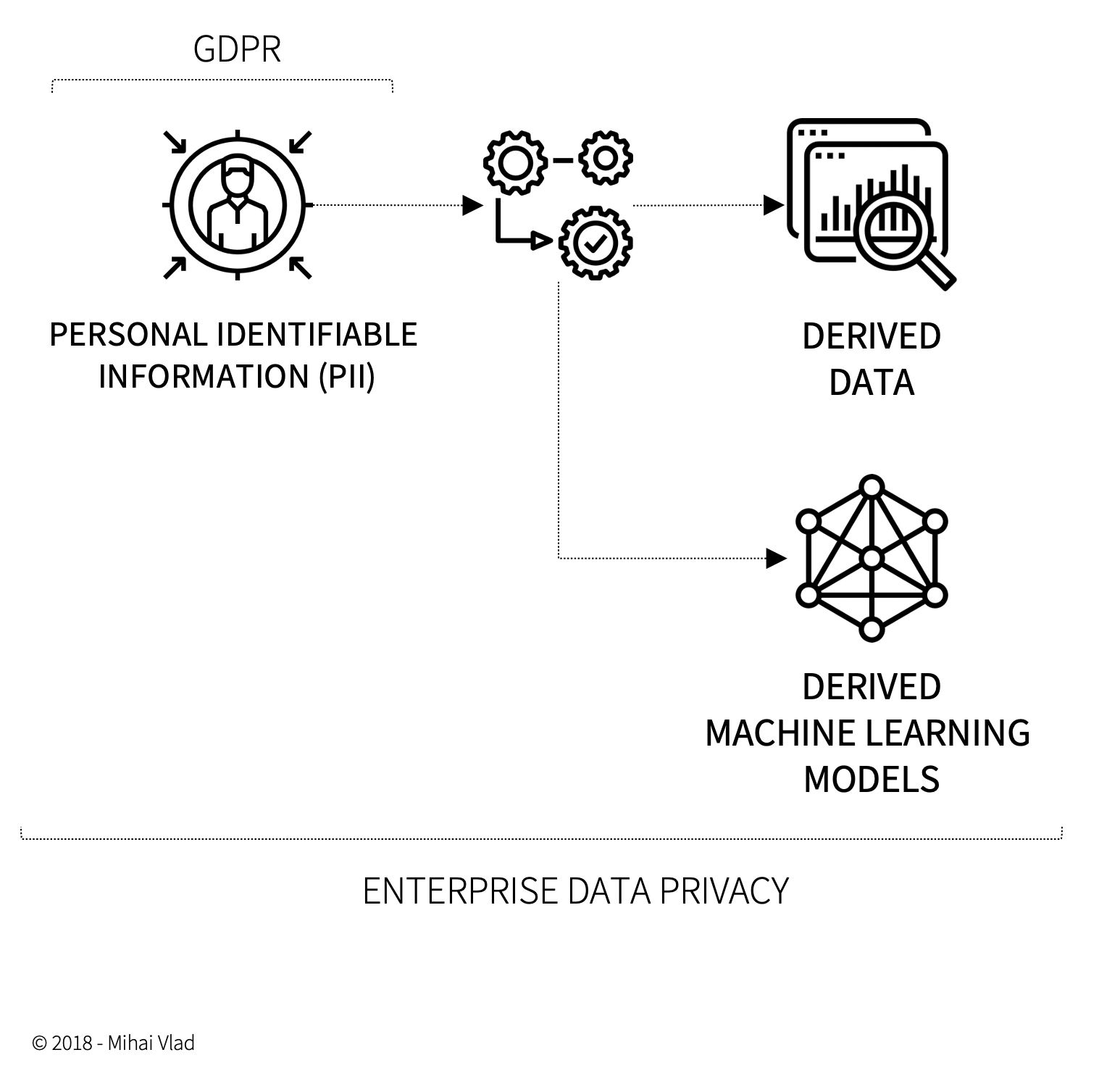
GDPR and Data Privacy pose an interesting challenge to all businesses using Personal Identifiable Information (PII) as training data for their Machine Learning models.
PIIs include names, addresses, phone numbers, age, gender, eye colour, weight, medical records, car registration plates, and even digital identifiers such as IP addresses, or geo-tracking data. The combination of a just a few of these data points can make it fairly easy to identify an individual. This can happen even if the data is anonymised – a good example being an experiment where a Netflix dataset was partially de-anonymised by blending it with public IMDb records.
GDPR allows the owners of this data – the individuals – to have this data erased (if they are a EU citizens).
So what happens if part of this data was used to train a Machine Learning model?
In theory, the model should be retrained, after the data is erased.
However, this process can be cost prohibitive, so business will likely avoid it. Also, if a “black-box” neural network is used, it makes it almost impossible to trace back the original PII, and prove that it was used in building the model.
This suggests that while GDPR will unlikely to affect the models themselves.
Nevertheless, the question stands – who owns the derived models (or the derived data) originating from PIIs?
One can argue that the individuals own them, as they own a share of the data used to build the models.
Equally, businesses can claim that the models are their Intellectual Property (IP), and that the contribution of a single PII is negligible for a large machine learning model trained on millions of data points.
Both arguments are valid, yet here are two more question that can help:
- If the models are the real IP and competitive differentiator, why are business open-sourcing the algorithms but not open-sourcing the training data?
- What would these businesses sell if raw PIIs disappeared overnight?
What is certain is that the conversations will become more detailed and will likely extend from Personal Data to Enterprise Data.
Data Privacy, Security and Control will become the foundation of any Mature Enterprise AI or Machine Learning solution.
These will not only address the input training data (just because regulation demands it), but will include the Derived Data and the Derived Models.
PS
A big shout out to Linear Digression – a great Machine Learning podcast series, who covered some of these points on Data Privacy.





